La comprobación del teorema de Myhill y Nerode nos proporciona un
hecho muy importante: el autómata basado en las clases de equivalencia
es el autómata mínimo dentro de todos los posibles autómatas
finitos deterministas y completos que aceptan el mismo lenguaje,
porque un tal autómata ![]() definiría un refinamiento de
definiría un refinamiento de
![]() , es decir,
, es decir,
![]() y el
AFD de las clases de equivalencia
y el
AFD de las clases de equivalencia ![]() representa las mismas clases
representa las mismas clases
![]() , entonces
, entonces
![]() .
.
Una pregunta surge: ¿Cómo sabemos si un AFD ![]() ya es mínimo?
ya es mínimo?
Pues, ![]() no es mínimo, si
no es mínimo, si
En tal caso, podemos unir los dos estados en un único estado.
Basta con `realizar las pruebas' con todas las palabras ![]() con
con
![]() porque no hace falta visitar un estado dos veces.
porque no hace falta visitar un estado dos veces.
Con dicho argumento describimos el algoritmo de minimización (sin comprobación) a continuación.
Decimos que dos estados ![]() y
y ![]() son distinguibles (o no-equivalentes)
si existe una palabra
son distinguibles (o no-equivalentes)
si existe una palabra ![]() que nos lleva desde
que nos lleva desde ![]() a un estado final
pero no desde
a un estado final
pero no desde ![]() , o al revés, es decir:
, o al revés, es decir:
El algoritmo calculará la relación de distinguibilidad (o no-equivalencia) entre los estados y contiene 5 pasos.
para cada parejano marcada y para cada símbolo
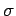 si
siestá marcada, también se marca
Ejemplo: partimos del siguiente AFD completo:
![]()
| - | |||||
| - | - | ||||
| - | - | - | |||
| - | - | - | - | ||
| - | - | - | - | - |
| - | 1 | ||||
| - | - | 1 | |||
| - | - | - | 1 | ||
| - | - | - | - | 1 | |
| - | - | - | - | - |
| - | 2 | 3 | 1 | ||
| - | - | 4 | 1 | ||
| - | - | - | 5 | 1 | |
| - | - | - | - | 1 | |
| - | - | - | - | - |
![]()
Observa que en la construccón del autómata podemos comprobar de cierta manera la corrección de la tabla: cuando recorremos todas las aristas del autómata original, tenemos que o bien añadir o bien encontrar su homóloga en el autómata en construcción.
El paso 4 se puede implementar más eficiente. En vez de mirar tantas veces las parejas no marcados, se mantiene listas de espera que se marcan recursivamente. Observamos:
Con está mejora el algoritmo tiene complejidad
![]() .
.