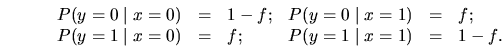
Arno Formella
La página incial del curso es:
http://formella.webs.uvigo.es/doc/tc03
Estos apuntes se acompaña con ilustraciones en pizarra dónde se explica las notaciones y algunos de los conceptos.
El texto es meramente una brevísima introducción (5 horas) a la teoría de la información.
¿Qué es información?
una opinión:
es decir, la información depende del estado de ambas partes.
intercambio de información con mutuo acuerdo, es decir, fuente y destino han acordado un protocolo para interpretar los símbolos intercambiados entre ellos
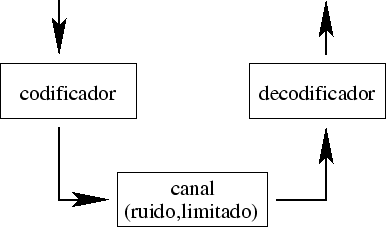
el canal de comunicación puede ser no-perfecto (p.ej., modem--línea telefónica--modem, satélite--propagación--tierra, memoria--disco--memoria)
la transmisión no se puede ver solamente en el sentido de espacio, sino también en el tiempo
si no hay protocolo establecido entre fuente y destino, el destino puede intentar averiguar el proceso de la fuente como manda la información
la teoría de información se dedica a los problemas de:
canal binario simétrico:
![\includegraphics[width=15cm]{bisymchn.eps}](img2.png)
Ejemplo: disco duro
asumimos canal binario simétrico para leer y escribir los bits al disco con una probabilidad de fallo de 0.1%
para que el disco sea útil, necesitamos una probabilidad de
![]() intercambiando 1 GByte cada día durante 10 años.
intercambiando 1 GByte cada día durante 10 años.
códigos de repetición
usamos para cada bit tres bits y decidimos por voto mayoritario

![\includegraphics[width=\textwidth]{repet.eps}](img7.png)
(7,4)-Hamming códigos
se manda en vez de 4 bits 7 bits
codificación:
| 0000 | 0000000 |
| 0001 | 0001011 |
| 0010 | 0010111 |
| 0011 | 0011100 |
| 0100 | 0100110 |
| 0101 | 0101101 |
| 0110 | 0110001 |
| 0111 | 0111010 |
| 1000 | 1000101 |
| 1001 | 1001110 |
| 1010 | 1010010 |
| 1011 | 1011001 |
| 1100 | 1100011 |
| 1101 | 1101000 |
| 1110 | 1110100 |
| 1111 | 1111111 |
se observa: cada pareja se distingue por lo menos en 3 bits
¿Cómo se ha construido la table?
se puede describir la construcción del código también con una multiplicación con una matriz:
![\begin{displaymath}
{\mathbf t}=
{\left[ \begin{array}{cccc}
\tt 1 &\tt0 &\tt0 ...
... 1 &\tt0 &\tt 1 &\tt 1 \end{array} \right] } \cdot {\mathbf s}
\end{displaymath}](img10.png)
descodificación:
se podría buscar la palabra que menos se destingue de la palabra transmitida (según su distancia Hamming)
o mejor
se calcula el síndrome que es el vector de bits que indica donde se ha violado la paridad
| síndrome |
000 | 001 | 010 | 011 | 100 | 101 | 110 | 111 |
| cambia | nada |
el proceso de codificación solamente funciona adecuadamente si se asume que se ha cambiado un solo bit durante la transmisión
también se puede expresar el cálculo del síndrome con una multiplicación con una matriz:
![\begin{displaymath}
{\mathbf z}=
\left[
\begin{array}{ccccccc}
\tt 1&\tt 1&\tt ...
...1&\tt 1&\tt0&\tt0&\tt 1
\end{array} \right] \cdot {\mathbf r}
\end{displaymath}](img19.png)
diagrama que relaciona tasa de transmisión con probabilidad de fallo
![\includegraphics[width=\textwidth]{rateprop.eps}](img20.png)
![\includegraphics[width=\textwidth]{hamming.eps}](img21.png)
Teorema (Shannon):
La tasa máxima (=capacidad) de un canal binario simétrico que permite la transmisión con error arbitrariamente pequeño se calcula como
![\begin{picture}(1500,900)(0,0)
\font\gnuplot=cmr10 at 10pt
\gnuplot
\sbox{\plotp...
...0pt}{0.736pt}}
\put(799.0,83.0){\rule[-0.200pt]{3.373pt}{0.400pt}}
\end{picture}](img23.png)
entonces, con el código apropriado basta con 2 discos duros (que sean lo suficientemente grande para almacenar un bloque) para garantizar una probabilidad de error tan pequeña como se desea, si la probabilidad de fallo en un bit es 0.1
Notaciones:
|
|
alfabeto con |
|
|
distribución de probabilidades discretas |
con
 y y |
|
| salida (o valor) de una variable aleatoria | |
|
|
ensemble, si
|
entonces:
abbreviación:
![]() dependiendo del contexto
dependiendo del contexto
Ejemplo:
|
![\begin{picture}(2,28)(-28,0)
\put(-28,0.15){\makebox(0,0)[bl]{
% includegraphics...
...0.19
% put(-28.65,1 )\{ makebox(0,0)[r]\{\{ verb+-+\}\}\} % 0.19
\end{picture}](img38.png)
|
Notaciones:
| probabilidad de un subconjunto
|
|
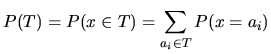 |
|
| ensemble unido | |
| salida (o valor) de una variable aleatoria de un ensemble unido | |
|
|
|
| las dos variables no son necesariamente independiente | |
| probabilidad unida | |
|
|
dado un ensemble unido:
Vocabulario:
| probabilidad marginal |
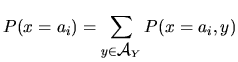 |
| probabilidad condicional |
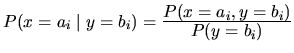 |
| si
|
|
| probabilidad que |
Ejemplo:
![\includegraphics[width=\textwidth]{joint.eps}](img52.png)
![]() denota bajo que condición se asume las probabilidades
denota bajo que condición se asume las probabilidades
Regla de producto (o regla de cadena):
Regla de suma:
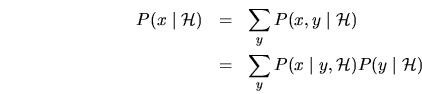
Regla de BAYES:
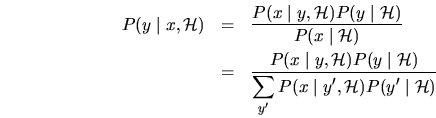
Vocabulario:
| independencia | dos variables aleatorias |
|
|
Ejemplo:
Solución:
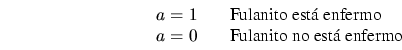
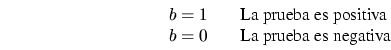
probabilidades condicionales:
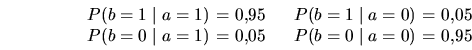
probabilidades marginales (de ![]() ):
):
probabilidad marginal (de ![]() );
);
probabilidad que Fulanito esté enfermo:
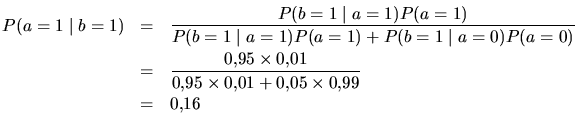
es decir: solamente un 16%
si ![]() la probabilidad baja a un 1.87%
la probabilidad baja a un 1.87%
Recomiendo leer la sección 2.3 del libro.
Notaciones:
| contenido de información de una salida |
|
|
|
|
| entropía de un ensemble | |
| es el contenido de información medio de una salida de un ensemble | |
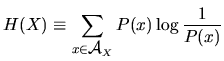 |
|
|
|
|
|
| 1 | a | .0575 | 4.1 |
| 2 | b | .0128 | 6.3 |
| 3 | c | .0263 | 5.2 |
| 4 | d | .0285 | 5.1 |
| 5 | e | .0913 | 3.5 |
| 6 | f | .0173 | 5.9 |
| 7 | g | .0133 | 6.2 |
| 8 | h | .0313 | 5.0 |
| 9 | i | .0599 | 4.1 |
| 10 | j | .0006 | 10.7 |
| 11 | k | .0084 | 6.9 |
| 12 | l | .0335 | 4.9 |
| 13 | m | .0235 | 5.4 |
| 14 | n | .0596 | 4.1 |
| 15 | o | .0689 | 3.9 |
| 16 | p | .0192 | 5.7 |
| 17 | q | .0008 | 10.3 |
| 18 | r | .0508 | 4.3 |
| 19 | s | .0567 | 4.1 |
| 20 | t | .0706 | 3.8 |
| 21 | u | .0334 | 4.9 |
| 22 | v | .0069 | 7.2 |
| 23 | w | .0119 | 6.4 |
| 24 | x | .0073 | 7.1 |
| 25 | y | .0164 | 5.9 |
| 26 | z | .0007 | 10.4 |
| 27 | - | .1928 | 2.4 |
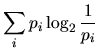 |
4.1 | ||
Reglas para la entropía:
positivo:
confinado:
ensembles unidos ![]() e
e ![]() :
:
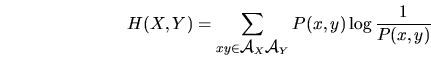
recursividad simple:
recursividad general:
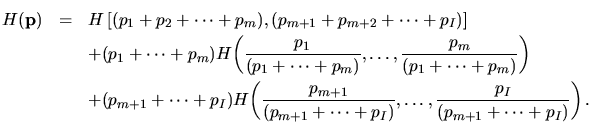
entropía relativa (o KULLBACK-LEIBLER divergencia)
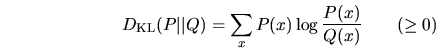
siendo ![]() y
y ![]() dos distribuciones de probabilidades sobre el
mismo alfabeto
dos distribuciones de probabilidades sobre el
mismo alfabeto
compresión de datos, modelado de datos, y eliminación de ruído tienen mucho en común
¿Cómo se puede medir información?
Ejemplo con las 12 bolas...
según SHANNON medimos el contenido de información de un símbolo emitido por una fuente, con el logaritmo de base 2 de su probabilidad de aparencia.
¿Porqué el logaritmo?
porque para variables aleatorias independientes, es decir, con
![]() tenemos:
tenemos:
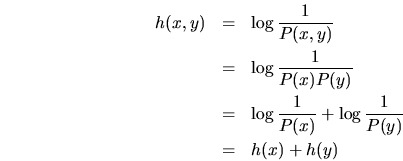
es decir, justamente sumamos sus contenidos de información individuales para obtener la información si ambos eventos ocurren a la vez.
el valor obtenido se puede interpretar como el número de bits necesarios para codificar la información.
¿Cuántos bits de información están escondidos en el ejemplo con las bolas?
¿Cuántos bits de información se gana con un uso de la báscula?
¿Qué propriedad tiene una solución óptima?
en cada uso de la báscula hay que intentar equilibrar las probabilidades de todos los posibles salidas del experimento.
por ejemplo, 6 contra 6 bolas núnca puede dar el caso de equilibrio.
![\includegraphics[width=15cm]{bolas.eps}](img87.png)
¿Hay otra estrategia?
la comprobación del teorema de SHANNON trata también del caso que las probabilidades no son uniformes.
siguimos directamente con el libro ...